Simplify End-to-End AI Testing
Like Playwright for your AI system. Write assertions, run in CI, and get human-readable reports. No ML overhead. No vendor lock-in.
import { evaluate, expect } from 'evaliphy';
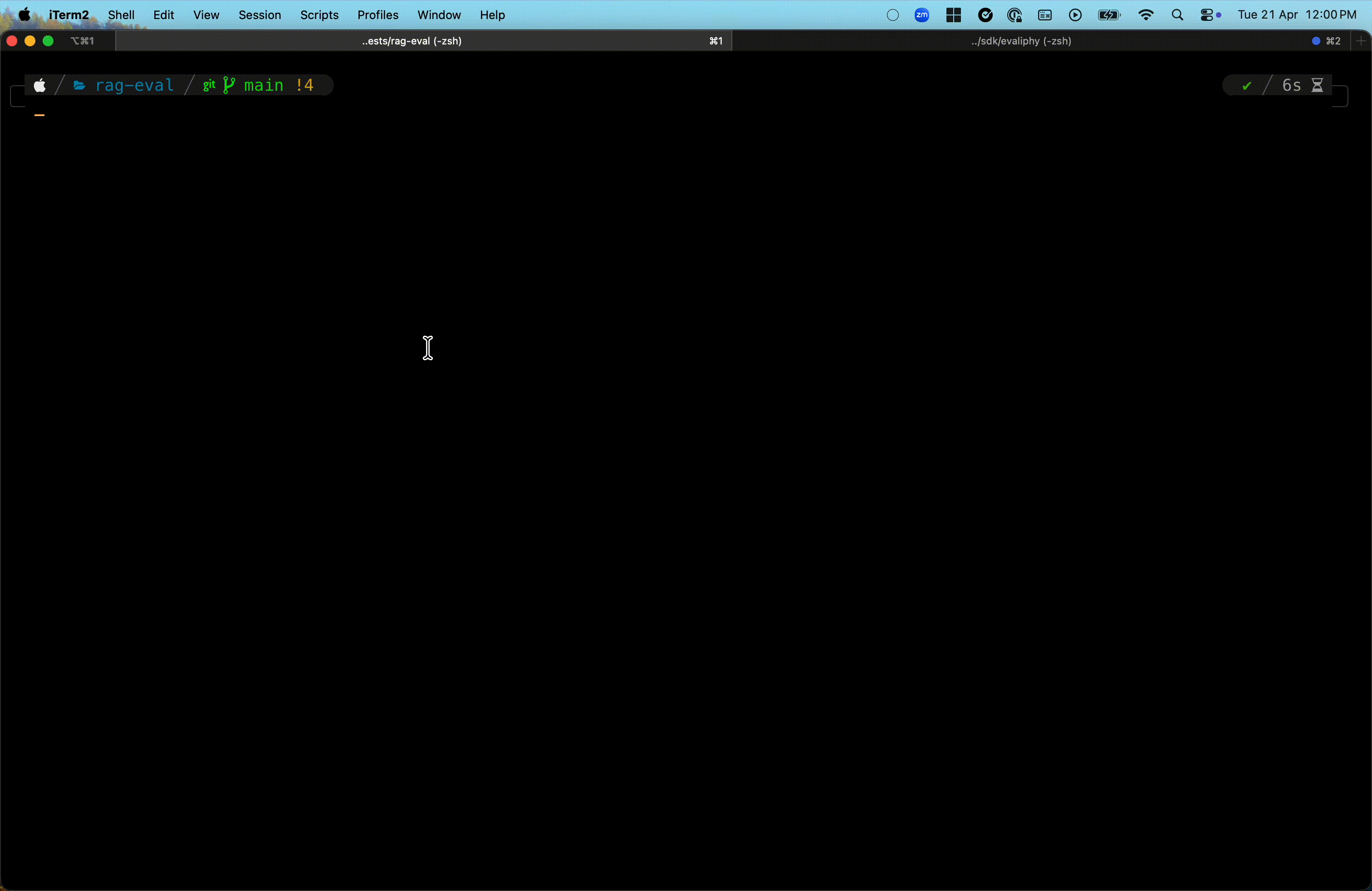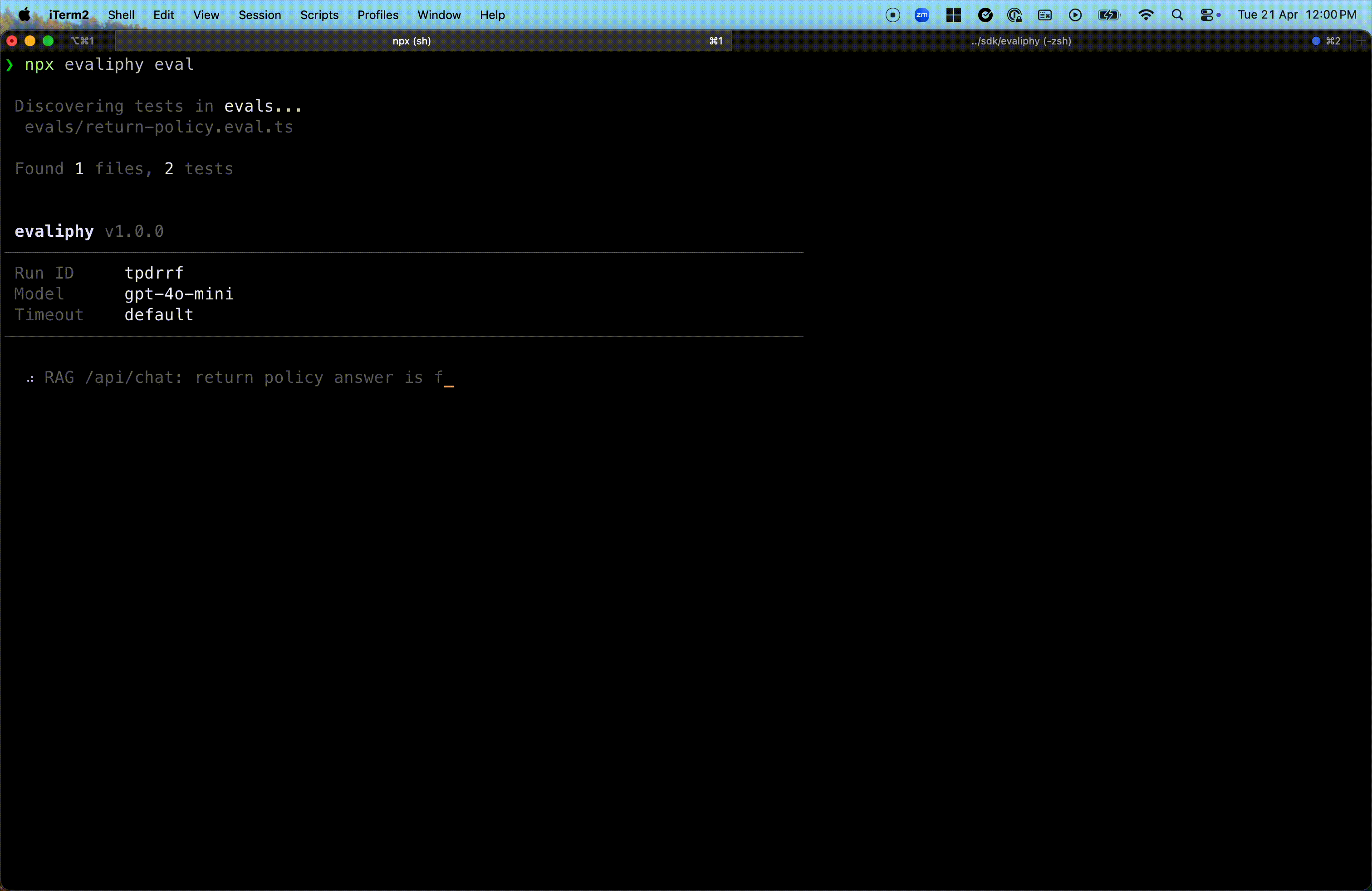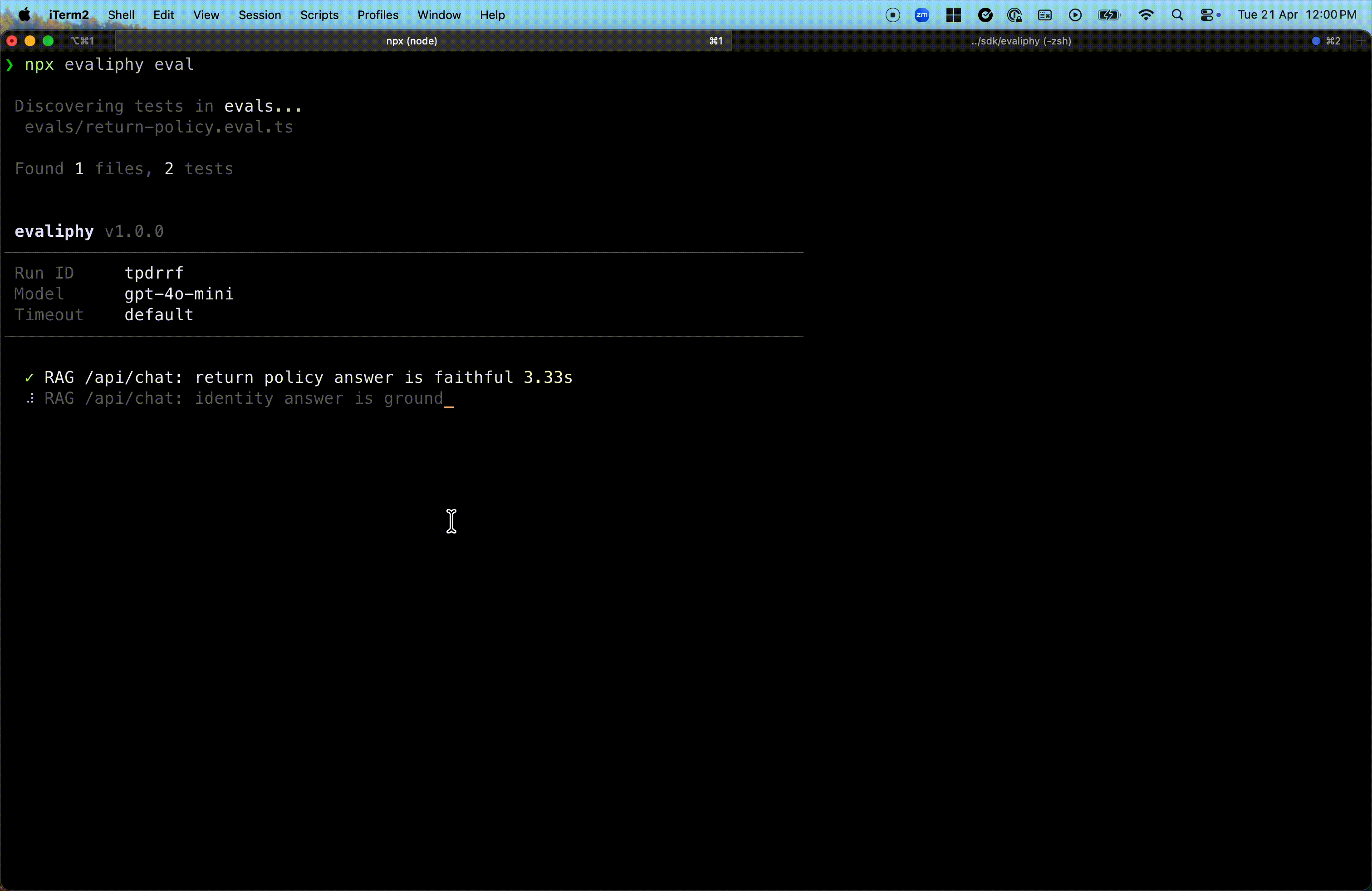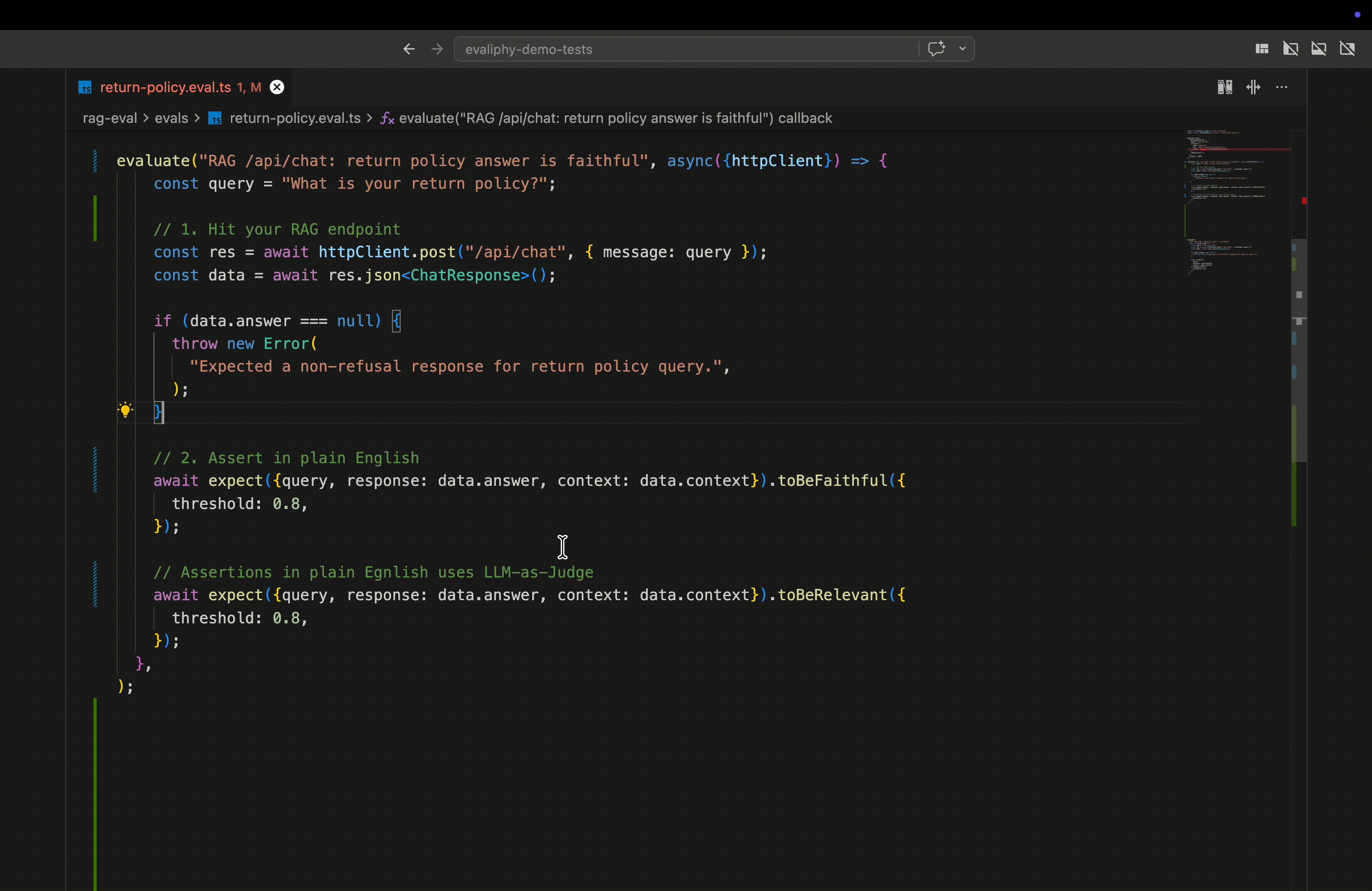
evaluate("RAG /api/chat: return policy answer is faithful",
async ({httpClient}) => {
const query = "What is your return policy?";
const res = await httpClient.post("/api/chat", {message: query});
const data = await res.json<ChatResponse>();
await expect(query, data.context, data.answer).toBeFaithful({
threshold: 0.8,
});
await expect(query, data.context, data.answer).toBeRelevant();
await expect(query, data.context, data.answer).toBeGrounded();
await expect(data.answer).toBeHarmless();
await expect(data.answer).toBeCoherent();
});
Why Evaliphy Exists
We built Evaliphy because AI testing should feel as straightforward as API testing: write assertions, run checks in CI, and get clear reports that drive immediate action.
The Core Gap
- ✅ Your teams already ship with assertion-based tests
- ✅ CI/CD already enforces quality for every release
- ❌ AI testing often drifts into notebook-heavy, research-first workflows
- ❌ Results are frequently too metric-heavy for fast product decisions

Human-readable evaluation reports
Get detailed, human-readable reports with LLM-judge reasoning.

Four Reasons Teams Choose Evaliphy
Familiar Mental Model
Test AI the same way you test APIs. Use assertions your team understands:toBeFaithful(),toBeRelevant(), andtoBeGrounded().
No Vendor Lock-In
Open source by default. Bring your own provider, own your test data, and run anywhere from local to CI.
No ML Overhead
No notebooks, no tuning pipelines, and no research stack. Just write assertions, run tests, and review results.
Human-Readable Reports
Understand failures quickly with plain-language reasoning and clear pass/fail outcomes you can act on in CI. Run with the standardnpx evaliphy run command.
Quick Comparison
Compare approaches, not just tools.
| Aspect | Evaliphy | Research Tools | Prompt Testing |
|---|---|---|---|
| Mental Model | Assertions like API tests | Research and optimization | Prompt iteration loops |
| Workflow | CI/CD pipeline | Notebook and experiments | CLI or web prompt runs |
| Setup Time | Minutes | Hours | Minutes |
| ML Knowledge Required | None | Significant | Minimal |
| Vendor Lock-In | None (open source) | Possible | Possible |
| Best For | Production AI testing in CI | Benchmarking and fine-tuning | Prompt engineering |
AI Testing Like Everything Else
Same Assertion Mindset
Use familiar expectations for AI quality, not new research paradigms.
- • Playwright tests UI flows
- • Evaliphy tests AI responses
- • Both use clear pass/fail assertions
Open by Design
No proprietary lock-in. Keep ownership of your tests, results, and workflows.
- • Open source framework
- • Works with major LLM providers
- • Run local or inside CI/CD
Built for Shipping Teams
Move from manual checks to repeatable AI quality gates before release.
- • Catch regressions before users do
- • Share human-readable reports across teams
- • Keep AI testing in your normal workflow
Ready to simplify AI testing?
Start testing any AI system with simple assertions, CI integration, and reports your team can read instantly.