How to Build Evaluation Datasets That Actually Catch Production Failures
 Golden datasets are evaluation infrastructure, not artifacts. Most teams treat them as a one-time deliverable: collect examples, label them, ship them, move on. The result is predictable. Metrics that look good in pre-release testing diverge sharply from production performance. Regressions surface in production that the dataset should have caught. Datasets become stale within months because they capture assumptions about user behavior that no longer hold.
Golden datasets are evaluation infrastructure, not artifacts. Most teams treat them as a one-time deliverable: collect examples, label them, ship them, move on. The result is predictable. Metrics that look good in pre-release testing diverge sharply from production performance. Regressions surface in production that the dataset should have caught. Datasets become stale within months because they capture assumptions about user behavior that no longer hold.
The distinction between teams that maintain reliable AI systems and those that don't often comes down to how they treat their golden datasets. Not as test data, but as living specifications—versioned, continuously refined, with structured feedback loops that connect production failures directly back to the evaluation suite.
This is infrastructure. It requires the same rigor you'd apply to your codebase.
Define the Evaluation Contract
Before collecting a single example, establish what the dataset is for. This is not a casual decision—it shapes which data you need, how you label it, and what metrics matter.
The evaluation contract has three elements:
| Element | Questions | Why It Matters |
|---|---|---|
| Decision | What will this dataset support? Ship vs. hold? Rollout vs. rollback? Model comparison? | Determines the cost of false positives vs. false negatives. A false positive (blocking a good release) costs velocity. A false negative (missing a real issue) costs production reliability. These tradeoffs are not symmetric. Your dataset design must reflect which risk you can't tolerate. |
| Scope | What outputs are you evaluating? Full response? Final answer + evidence? Confidence scores? Citations in isolation? | Many teams evaluate outputs without defining what "correct" means across different response types. You discover in production that your metrics don't correlate with user satisfaction because you were measuring the wrong thing. |
| Metrics | How will you measure success? Not vague goals ("high accuracy") but concrete thresholds tied to decisions. | "Ship if accuracy ≥ 92% on full dataset AND ≥ 88% on PII-handling subset" is actionable. "Achieve good results" is not. Thresholds without context are meaningless. |
Write this down. Make it a shared document. Teams that skip this step discover later that stakeholders had fundamentally different assumptions about what the dataset should prove.
Once the contract exists, design the coverage matrix—a systematic inventory of variations you need to test. Not abstract variations, real ones. For a customer support system: tickets by category (returns, billing, shipping, technical), by complexity (single-turn vs. multi-turn), by tone, and by outcome. For each meaningful combination, define target example counts.
Then apply the critical constraint: weight by cost of failure, not frequency. A PII leak happens in 0.1% of interactions but is catastrophic—your dataset should overrepresent it. An agent misunderstanding a simple question happens in 15% of cases but is recoverable—it needs less coverage. Most teams mirror production frequency, leaving their golden dataset mostly easy cases that catch regressions in the 85% while missing failures in the 0.1%.
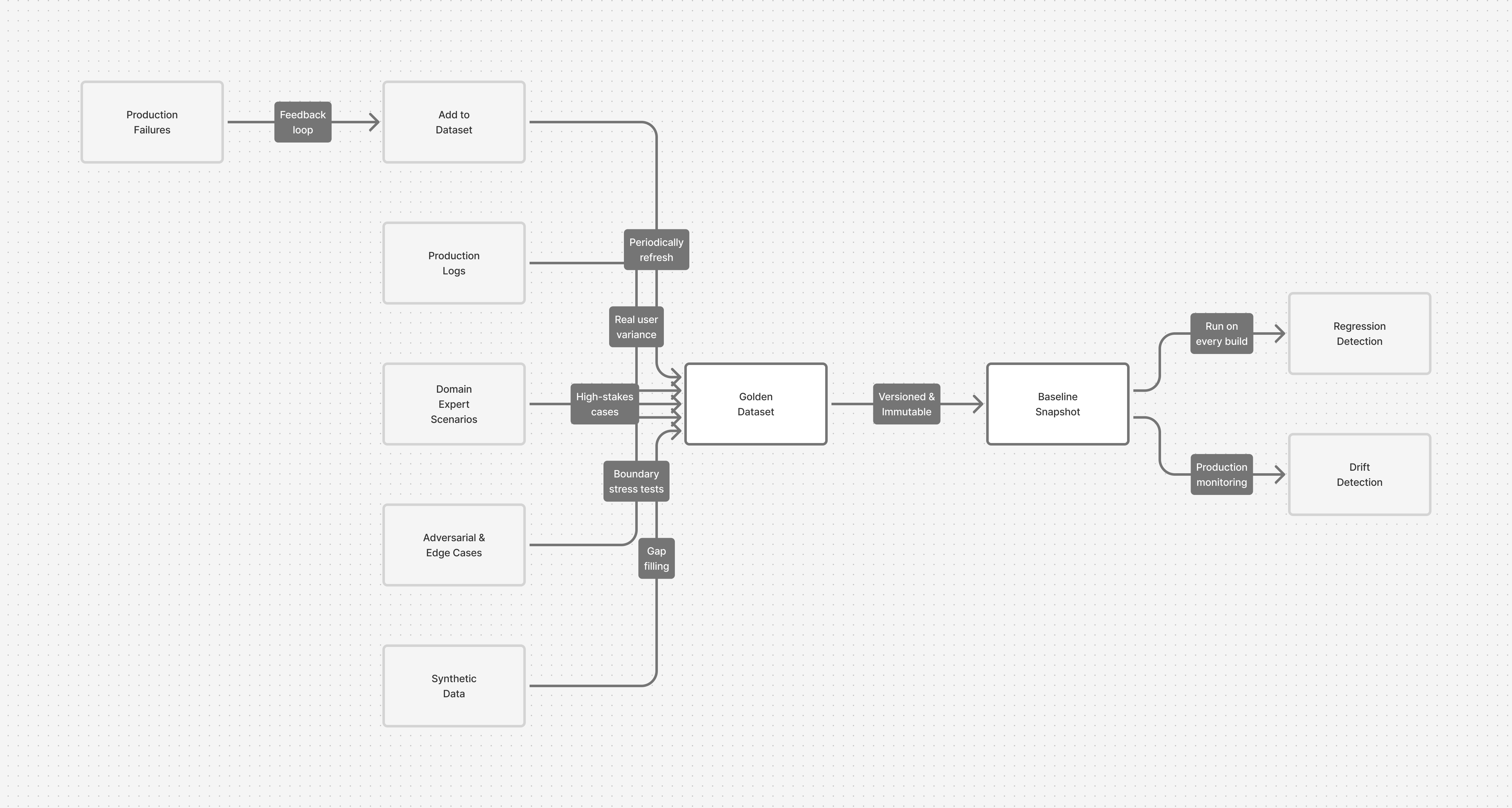
Source Data Systematically
A golden dataset requires four types of data, ranked by signal strength.
| Data Source | Characteristics | Best For | Limitations |
|---|---|---|---|
| Production logs (Anonymized user interactions) | Real user variance, actual intents, authentic edge cases. Thoroughly anonymized: strip PII, email patterns, account IDs, transaction details. Tagged by outcome. | Ground truth. Highest-quality foundation. What actually happens in your system. | Cannot reveal what you're missing. Shaped by your current system's limitations. |
| Expert scenarios (Domain SME-authored) | High-stakes, must-pass cases from lawyers, physicians, engineers. Catches edge cases experts know matter. Sourced through structured conversation: "What scenario would make you uncomfortable shipping this?" | Finding failure modes production logs won't surface. Stress-testing on domain-specific risk. | Time-intensive to produce. Limited to known unknowns. |
| Adversarial cases (Robustness testing) | Ambiguous inputs with multiple interpretations. Prompt injections. Simulated system failures (timeouts, API errors, rate limits). Tests guardrails and error handling. | Safety validation. Degradation testing. Ensuring the system fails gracefully under stress. | Need domain expertise to design well. Don't represent real user behavior. 10-20 per cycle is sufficient. |
| Synthetic data (LLM-generated) | Question-answer pairs, coverage gap filling, variations on known patterns. Scalable and cheap. | Scaling examples you know work. Filling specific coverage gaps quickly. | Weakest signal. Often looks plausible while missing real-world subtleties. Always validate with domain experts before production use. |
Composition guidance: A mature dataset typically allocates 60% production logs, 20% expert scenarios, 10% adversarial cases, 10% synthetic. Early-stage systems with minimal production data invert this—rely more on expert judgment and synthetic gap-filling until production volume grows.
Size for Your Stage
The assumption that evaluation datasets must be large prevents many teams from starting. They do not.
| Size | Timeline | Coverage | Use Case | What You Learn |
|---|---|---|---|---|
| 50–100 examples | 1–2 weeks | Major failure classes identified | MVP / proof of concept | Whether your evaluation approach is sound. Identifies major blindspots. |
| 200–500 examples | 3–6 weeks | Major use cases + documented edge cases | Production gate | Metrics reliable enough for shipping decisions. Real signal on whether the system is ready. |
| 1,000+ examples | Ongoing (months) | Comprehensive coverage + production failures | Mature systems | Continuous regression prevention. Production feedback loop working. Predictive of real-world performance. |
Critical mistake to avoid: Don't attempt to build the full dataset upfront. You'll spend months labeling based on assumptions about user behavior and failure modes. You'll ship. Within weeks, you'll discover production failures don't match your dataset. Your pre-built dataset becomes irrelevant.
Better approach: Start at 200 examples. Deploy as a gate. Learn which failure modes matter in production. Add examples from production failures. The dataset grows as you learn.
Establish a Labeling Standard
Ground truth is only as reliable as the labeling standard that produces it. Inconsistent labeling introduces noise that corrupts signal—worse than having no labels at all.
Your labeling specification must include:
| Requirement | Purpose | Example |
|---|---|---|
| Clear definitions with explicit criteria | Eliminate ambiguity in what counts as correct. Examples alone are insufficient. | Don't say "faithful response." Say: "Faithful response: factually accurate AND supported by ≥1 source document OR derivable from combining multiple sources." |
| Boundary cases and counter-examples | Show what just meets the threshold and what falls just short. | "This response is faithful (meets criteria). This response is not (missing source support). This one is borderline (state decision rule)." |
| Edge case handling and disagreement resolution | In domains with genuine expert disagreement, document whether you capture one school of thought or consensus. | For medical diagnosis: document if you're using consensus guidelines or allowing multiple valid approaches. |
| Metadata tags for debugging | Enable regression diagnosis instead of guessing. Pair every label with context. | For RAG: source domain, question ambiguity level, whether multiple valid answers exist, hallucination type if present. For summarization: original length, technical domain, abstract vs. extractive. |
| Inter-rater agreement measurement | Surface ambiguity and spec clarity problems early. | Use multiple independent labelers. Measure agreement. High disagreement = spec is unclear or examples are ambiguous (fix both). |
Implementation: Tags are the difference between "accuracy dropped 2%" and "accuracy dropped 2% specifically on long-form technical documents in the medical domain." The latter lets you diagnose. The former forces guessing.
Use multiple independent labelers. Disagreement signals either ambiguous examples (remove or clarify) or an unclear spec (refine it). Treat disagreement as a data quality signal, not a labeler performance problem.
Maintain as Living Artefacts
Your golden dataset is complete when your system is retired. Until then, it requires active maintenance.
| Maintenance Practice | Frequency | Responsibility | What It Prevents |
|---|---|---|---|
| Version and track changes | Every release | QA/Engineering | Inability to correlate metric changes with dataset changes. Lost context on why examples were added. |
| Close the feedback loop | Same-day | Production/QA | Recurring failures in production. Loss of opportunity to prevent the same failure twice. |
| Quarterly refresh | Every 3 months | QA lead | Dataset drift as real user behavior evolves. False confidence from stale test cases. |
| Monitor correlation | Ongoing | Metrics/Analytics | Discovering too late that your dataset is miscalibrated or has coverage gaps. |
Feedback loop mechanics: When a query in production exposes a failure, add it to the dataset within hours. Not next sprint. This failure becomes a regression test. The system never fails the same way twice. Requires: a process to flag interesting failures, extract and anonymize them, tag by outcome, and integrate into evaluation suite.
Quarterly refresh mechanics: Examine the last 1,000 production queries. Identify the 5-10 categories with highest failure rates not already well-covered in the dataset. Add examples to those slices. Retire examples that haven't appeared in production in six months. You're not rebuilding—you're maintaining coverage as actual user behavior evolves.
Correlation monitoring: Track which parts of your golden dataset show highest failure rates. Does your dataset's failure distribution match production's? If not, you're miscalibrated or have coverage gaps. Maintain a dashboard: dataset failure rates vs. production failure distribution. They should align.
It sounds challenging but it is not
You don't need to implement every element at once. Begin with this sequence:
Phase 1: Define the contract. Document your decision, scope, and target metrics. This is a one-day effort that prevents weeks of misdirected work.
Phase 2: Design coverage. Map out the real-world variations your system must handle. For each category combination that matters, define target example counts weighted by cost of failure.
Phase 3: Collect 200 examples. Source from production logs (primary), expert judgment (secondary), adversarial cases (10-20 examples), and synthetic gap-filling. Label them against a written spec. Measure inter-rater agreement. Fix the spec where labelers disagreed.
Phase 4: Deploy as a gate. Run this dataset on every build. Fail the build if metrics regress. This immediate feedback teaches you whether your coverage and metrics are calibrated to reality.
Phase 5: Close the loop. Establish a process: flag interesting failures in production, extract and anonymize them, add them to the dataset, run the gate again. This turns failures into regression tests.
Phase 6: Maintain. Quarterly refresh: align dataset composition with actual production failure distribution, retire stale examples, add coverage gaps.
This scales. At 50 examples you get MVP signal. At 200 you have a real gate. At 500 you're confident in your metrics. At 1000+ you're continuously improving based on production data. The dataset grows as you learn.
Golden datasets are not a feature to build when you have time. They are the specification of what your system should do. The regression test that prevents the same failure twice. The benchmark for release decisions. The foundation of reliable AI systems. Every week you operate without one is a week of decisions made on intuition rather than data.
The work compounds. Build it once. Update it forever.