How It Works
1. Write in Your Language
Use TypeScript. No Python. No notebooks. Just assertions in the language you already code in.
import { evaluate, expect } from 'evaliphy';
evaluate("Return Policy Chat", async ({ httpClient }) => {
const res = await httpClient.post('/api/chat', {
message: "What is your return policy?"
});
await expect({
query: "What is your return policy?",
response: res.answer,
context: "Items can be returned within 30 days."
}).toBeFaithful();
});
2. Test Your Real API
No mocks. No offline datasets. Call your actual endpoint. Get actual responses.
3. Run in CI
Works with GitHub Actions, GitLab CI, Jenkins—anywhere you run tests.
- run: npx evaliphy run
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
4. Get Readable Reports
See what passed, what failed, why it failed. Human-readable. Machine-parseable.
The Core Mechanism
At its heart, Evaliphy follows a simple but powerful workflow: Trigger → Execute → Judge → Report.
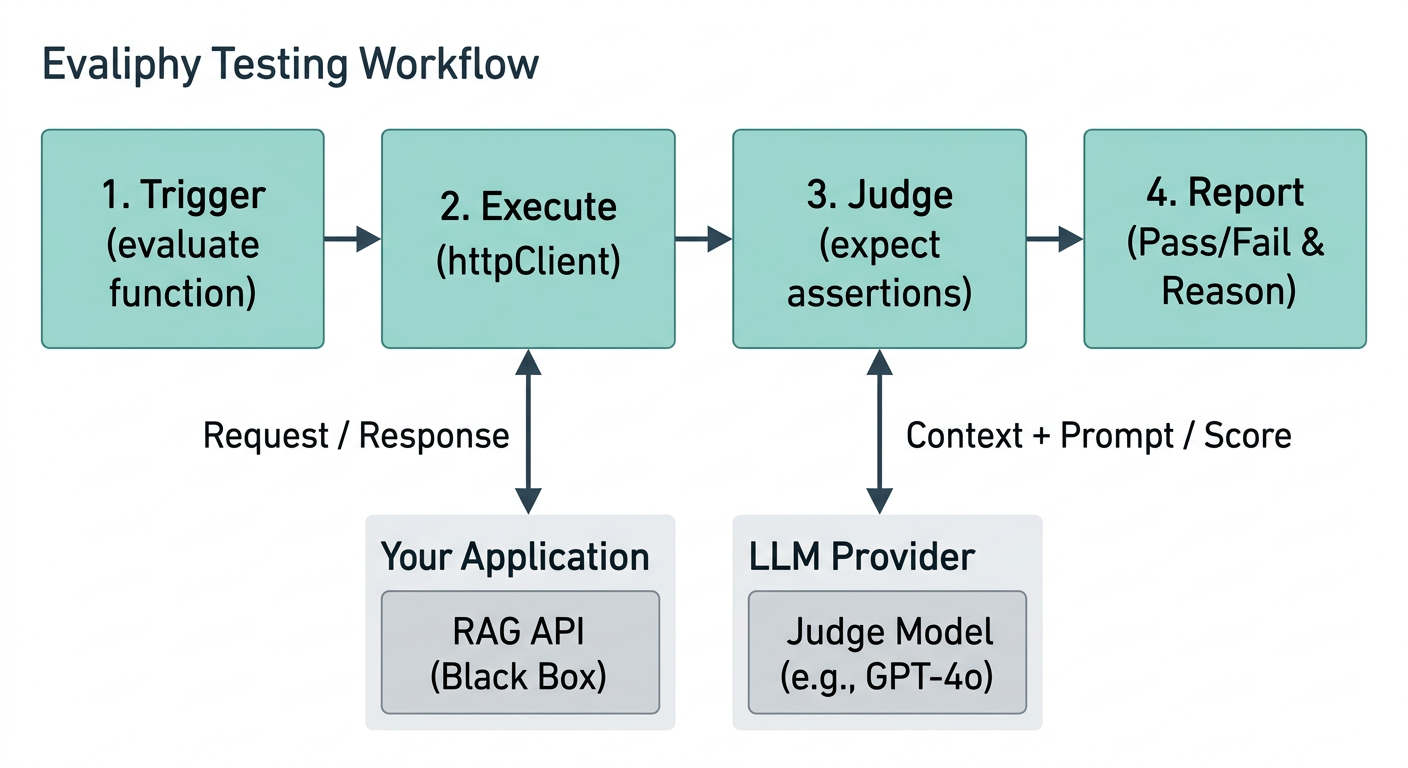
1. Trigger (The Evaluation File)
You write evaluations in TypeScript using the evaluate function. These files sit in your repository alongside your application code. When you run evaliphy eval, the CLI discovers these files and begins execution.
2. Execute (The HTTP Client)
Inside your evaluation, you use the built-in httpClient to make real requests to your running RAG API. This ensures you are testing the actual system that your users interact with, including all its prompts, retrieval logic, and infrastructure.
3. Judge (LLM-as-a-Judge)
When you call an assertion like expect(res).toBeFaithful(), Evaliphy:
- Collects the necessary data (Query, Response, and Context).
- Selects the appropriate Judge Prompt for that assertion.
- Sends the data and prompt to your configured Judge Model (e.g., GPT-4o).
- The Judge returns a numeric score (0.0 to 1.0) and a plain-English reason for that score.
4. Report (Feedback Loop)
Evaliphy compares the judge's score against your defined threshold.
- Pass: If the score meets the threshold, the test goes green.
- Fail: If it falls below, Evaliphy provides the judge's reasoning, helping you understand exactly why the response was considered poor quality.
Why This Approach?
By treating your RAG system as a black box, Evaliphy avoids the complexity of mocking internal vector databases or embedding models. Instead, it focuses on the observable behavior—the only thing that actually matters to your end users.